
Saya mengganti Cursor dengan pengaturan VS Code yang sepenuhnya lokal, dan saya melewatkan kurang dari yang diharapkan
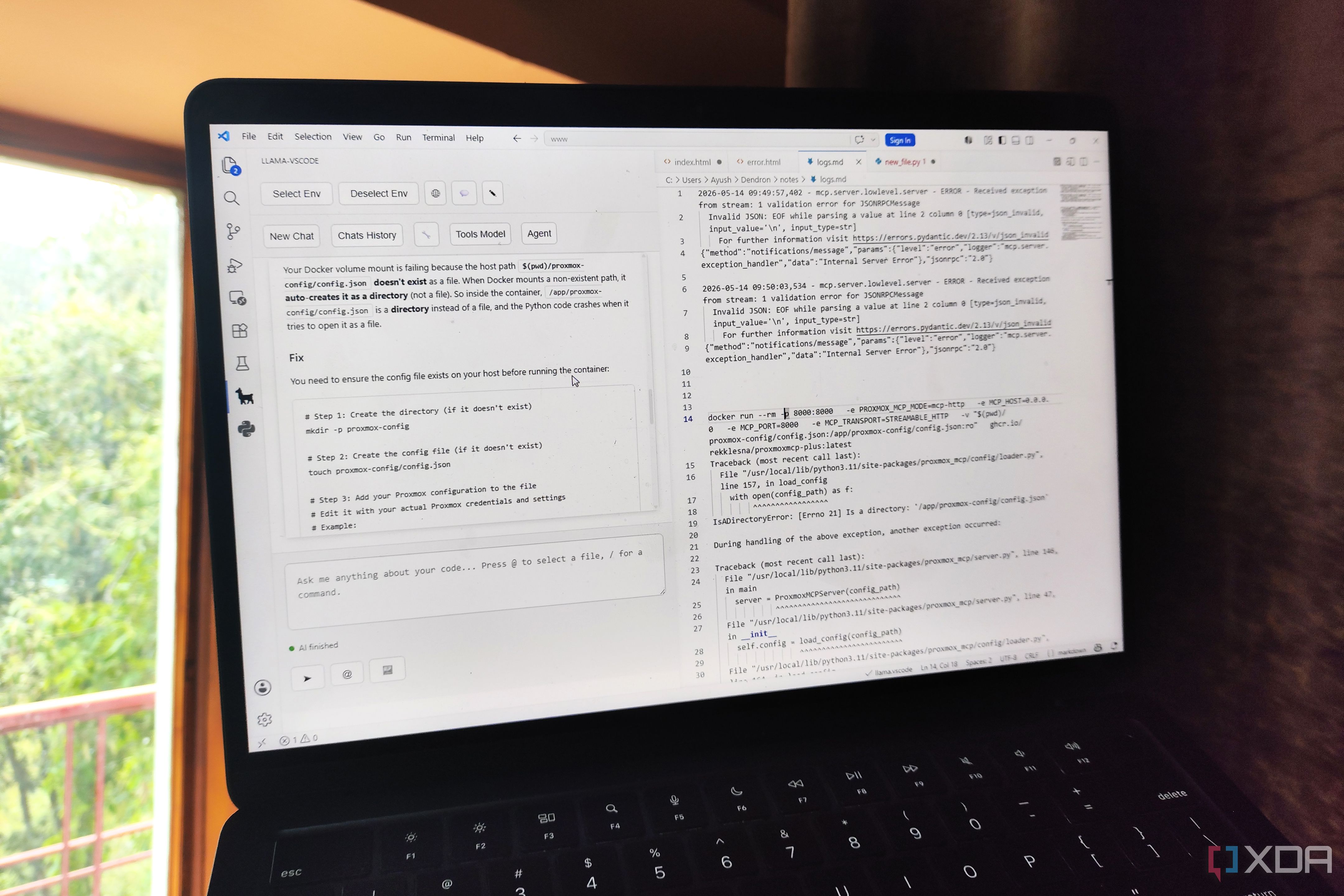
Mengingat alat AI dapat mengatasi tugas-tugas palsu yang sangat membingungkan, tidak dapat disangkal bahwa alat tersebut adalah anugerah bagi produktivitas. Namun karena hampir setiap platform berbasis cloud membebankan biaya berlangganan rutin untuk layanan bertenaga clanker mereka, kita mulai sampai pada titik di mana Anda bisa membayar ratusan dolar untuk menghindari batasan tarif pada platform coding. Faktanya, penggunaan token yang sangat dibatasi pada versi gratis Cursor dan Antigravity telah membuat saya menghindari penawaran mereka, dengan batas waktu yang terakhir khususnya menjadi hambatan besar bagi proyek-proyek di mana saya perlu menanyakan LLM beberapa kali untuk mendapatkan sesuatu yang berarti darinya. Sementara itu, saya sudah mulai bereksperimen dengan model MoE, dan dengan ekstensi yang tepat pada VS Code, model tersebut telah sepenuhnya menggantikan model cloud untuk tugas pengembangan saya. Terkait Saya menjalankan LLM lokal pada iGPU termurah Intel, dan ternyata hasilnya lumayan. Ini tidak sebanding dengan GPU khusus, tetapi Anda dapat menjalankan beberapa LLM ringan di N100. Ekstensi llama-vscode memicu petualangan coding saya. Saya telah memasangkannya dengan model MoE yang saya host di node lab rumah saya. Dulu ketika saya pertama kali mendalami LLM, sebagian besar saya terjebak dengan model 9B dan 12B. Meskipun cukup baik untuk menghasilkan teks OCR atau membuat tag untuk dokumen, hyperlink, dan catatan saya, keduanya jauh dari ideal untuk tugas pengkodean – dan bukan hanya pengkodean getaran. Kasus penggunaan paling umum untuk LLM di lab rumah saya adalah menanyakan mereka tentang proyek yang gagal, memeriksa log terminal, dan melakukan pemindaian kerentanan pada kode saya. Model berukuran kecil yang sesuai dengan GPU tingkat konsumen tidak memiliki kekuatan komputasi untuk tugas-tugas ini, terutama setelah Anda membandingkannya dengan pembangkit tenaga listrik yang dapat Anda manfaatkan dengan Cursor dan Antigravity. Namun, model Mixture-of-Experts membalikkan keadaan. Lagi pula, kemampuan untuk menghosting model 35B yang besar pada GPU VRAM 12 GB yang lemah tanpa mengalami penurunan kinerja yang besar atau menurunkan tingkat kuantisasi menjadikannya kekuatan yang harus diperhitungkan. Dan setelah menguji GPT-OSS-20B, Gemma-4-26B-A4B, dan Qwen3.6-35B-A3B dengan instance VS Code saya selama beberapa bulan terakhir, saya dapat mengonfirmasi bahwa keduanya sempurna untuk tugas-tugas pengembangan, dengan Qwen3.6 mampu bertahan melawan pesaingnya yang berbasis cloud. Sedangkan untuk perangkat pengkodean saya, VS Code – aplikasi asal Cursor dan Antigravity – berfungsi sebagai inti dari pengaturan saya. Saya awalnya menggunakan Lanjutkan selama masa saya di Ollama, tetapi setelah merasakan model MoE, saya beralih ke llama-vscode, yang berpasangan dengan sangat baik dengan instance server llama yang berjalan di server Proxmox dan stasiun kerja game saya. Karena ekstensi llama-vscode menerima semuanya mulai dari file kode hingga dokumen acak, kemungkinan halusinasi LLM saya semakin berkurang. Pasangkan dengan LLM yang tepat, dan dapat menghasilkan cuplikan kode yang berfungsi penuh, sementara fitur pelengkapan otomatisnya juga dapat diandalkan. Meskipun demikian, saya lebih beruntung dengan Qwen 2.5 Coder (varian parameter yang lebih rendah) sebagai model pelengkapan otomatis, karena Qwen3.6 dan Gemma 4 memerlukan beberapa detik untuk menghasilkan kode. Namun untuk obrolan sederhana berbasis RAG atau bantuan pemecahan masalah, LLM ini cenderung memberikan hasil yang akurat dalam waktu kurang dari satu menit. Terkait GPU lama Anda masih dapat menjalankan LLM besar – Anda hanya memerlukan penyesuaian yang tepat Ada banyak hal yang dapat Anda lakukan dengan model ini Termasuk utilitas yang diekspos melalui server MCP Aspek menarik lainnya dari llama-vscode adalah ia mendukung alur kerja agen, dan agen default cukup fleksibel untuk beradaptasi dengan sebagian besar situasi pengkodean. Namun, kesenangan sesungguhnya dimulai saat Anda mulai membuat agen untuk tugas khusus. Bahkan ada agen yang dirancang untuk membuat agen lain (dan sub-agen), dan itu berfungsi dengan baik selama saya memberikan penjelasan rinci tentang apa yang saya inginkan di bagian obrolan. Demikian pula, llama-vscode juga memungkinkan saya menyempurnakan berbagai aspek agen, dan saya dapat memilih jumlah alat yang tepat yang tersedia. Berbicara tentang alat, llama-vscode bekerja dengan server MCP, artinya saya dapat menggunakan LLM saya untuk mengontrol aplikasi tambahan, daripada hanya mengandalkan aplikasi tersebut untuk tugas pengkodean. Bagian terbaiknya? Saya tidak perlu membayar biaya berlangganan apa pun untuk penyiapan ini Fakta menyenangkan: Tugas inferensi burst tidak menghabiskan banyak energi Dibandingkan dengan LLM cloud yang dapat menghasilkan seluruh file kode dalam beberapa detik, waktu yang sedikit lebih lama yang dibutuhkan oleh model MoE saya untuk menjawab pertanyaan tidaklah buruk sama sekali. Jika ada, saya akan mengambil sedikit kelemahan kinerja ini karena kehabisan batas tarif setiap hari, terutama karena LLM lokal saya membuat saya tidak perlu membayar biaya berlangganan tambahan setiap bulan. Jika Anda bertanya-tanya tentang konsumsi daya stasiun kerja hosting LLM saya, tidak, model yang saya hosting sendiri hampir tidak berkontribusi pada tagihan energi saya. Anda tahu, ada kesalahpahaman besar tentang penggunaan LLM di komunitas yang mengutak-atik – meskipun model AI dapat menyedot sejumlah besar daya selama fase pelatihan, tugas inferensi adalah cerita yang berbeda. Saat saya menjalankan tugas yang didukung LLM, GPU saya hidup selama beberapa detik, memproses tugas, dan kembali ke keadaan menganggur. Malah, menjalankan server 24/7 menghabiskan lebih banyak watt daripada tugas inferensi, tapi saya sudah menggunakan satu stasiun kerja untuk eksperimen Proxmox saya, sementara stasiun kerja lainnya adalah mesin game/pengeditan video/pengkodean utama saya. Lalu ada keuntungan privasi dengan menghubungkan LLM lokal ke dokumen lab rumah saya, basis kode akses awal, dan proyek rahasia. Sungguh, beberapa pengorbanan kinerja sepadan dengan sifat pribadi dan bebas langganan dari pengaturan VS Code lokal saya.
Diterbitkan : 2026-06-03 10:00:00
sumber : www.xda-developers.com




{kind=link}